Il y a déjà plusieurs mois que j’ai entamé en compagnie d’Antoine Le Calvez une série d’excursions dans l’univers des bases de brevets. Ce type de campagnes exploratoires dans de nouveaux sets de données est l’occasion, pour l’Atelier de Cartographie, d’être confronté à de nouveaux défis en termes de rendus cartographiques, d’éprouver nos méthodes, d’affûter les outils en précision, de varier les échelles, d’imaginer de nouveaux filtres statistiques ou graphiques pour les données. On ne verra donc pas dans ce compte-rendu une tentative de description exhaustive d’un domaine que nous avons à peine arpenté et dont ne sommes pas spécialistes. Il ne s’agit que d’un simple exercice de style, l’occasion d’éprouver nos savoirs-faires et notre imagination, préparant ainsi les solutions de visualisation qui demain peupleront une plateforme en ligne. Nous ne sommes pas juristes ni experts en économie industrielle et seul a compté pour nous le processus exploratoire du corpus de notices étudié, avec ses chemins et son rythme. Durant cet arpentage et nos premières mesures, certaines propriétés topologiques des masses de brevets nous ont parues suffisamment remarquables pour être cartographiées, en déballant ici ou là notre boîte à outils, composée de sets de données extraites du web, Excel ou un GoogleDoc, Gephi, quelques scripts, Inkscape ou Illustrator pour les finalisations graphiques. En voici quelques clichés.
1) Des données et une boussole.
DES DONNEES. Les données brevet représentent un territoire encore peu connu à grande échelle (du moins à ma connaissance et comme le remarque M.E.J. Newman dans Networks). Je me représente spontanément la géographie documentaire des bases de brevets sous la forme d’une matrice de graphe assez « sparse » (clairsemée) avec ici et là des « noyaux » très denses et très hiérarchisés en termes de citations (là ou s’affrontent, ou s’associent par familles, les technologies ou les procédés). Il s’agit pourtant d’un espace stratégique dans une économie encore largement fondée sur la propriété intellectuelle. Bien que GooglePatent permette aujourd’hui d’y accéder (pour ceux qui, comme nous, n’ont pas d’accès à des bases structurées payantes), la rareté des informations sur les formes et l’évolution de ce vaste système documentaire s’explique peut-être par le fait que nombre d’études statistiques (voire de cartographies) sont produites par des cabinets spécialisés en veille informationnelle et juridique.
L’univers des brevets est constitué d’objets documentaires complexes mais normés, ce qui les rend à priori assez exploitables ou aisément cartographiables. Ils peuvent comporter plusieurs types de descripteurs (inventeur-titre-année de dépôt-exploitant…) et documents associés. Dotés d’identifiants uniques (variables notamment selon le niveau de protection ou le pays), ils sont associés par des liens de citations (donc des liens orientés de la source vers la cible citée), tout comme les liens de citations entre publications scientifiques. Comme ces dernières, les brevets apparaissent successivement au cours du temps dans les bases: les liens s’y accumulent donc essentiellement en direction de « couches » temporelles antérieures, ce qui vaut à leur topologie la propriété particulière d’être a-cyclique (si un brevet A cite un brevet B antérieur, que B cite C lui-même antécédent, alors il n’existe pas de liens possibles entre C et A qui produirait un cycle complet).
Nous avons choisi (arbitrairement) la thématique de la technologie numérique « MPEG », probablement parce qu’elle est présente dans la plupart de nos appareils numériques, et surtout mobiles. L’acronyme « MPEG » correspond au « Moving Picture Experts Group » qui a commencé à se réunir en 1988, sous l’autorité de l’ISO dans le domaine des technologies de l’information. L’objectif de ce groupe d’experts en électronique, informatique et télécommunications a été de définir différents standards pour la compression de signal vidéo, audio mais aussi aujourd’hui multimédias et interactifs avec toutes les applications web et/ou les dispositifs numériques mobiles. Etant donné le poids commercial des industries numériques, on peut considérer qu’il s’agit d’un domaine central de l’économie mondialisée actuelle.
L’extraction des données a été réalisée par phases successives pour régler les scripts d’automatisation et s’est concentrée sur la base de l’USPTO (United States Patent and Trademark Office) qui, malgré sa focalisation sur les brevets nord-américains, présente l’avantage d’associer à chaque brevet des données relativement exhaustives sur les liens de citations, sans oublier des fonctionnalités comme le patent-dashboard. Dans une autre exploration consacrée à l’analyse des réseaux de partenaires du CNRS en termes de dépôt (à venir sur ce blog), nous avons préféré utiliser GooglePatent qui permet d’appliquer aux brevets toutes les technologies Google (notamment la production de ces fameuses « inférences » qui permettent de regrouper pour un même acteur la plupart de ses affiliations) et qui indexe de plus en plus précisément les bases américaines, européennes et japonaises.

En termes de méthodologie d’extraction, nous sommes « partis » d’un brevet particulièrement « focus » sur notre sujet et qui est associé dans la base à de nombreux liens de citations (entrants et sortants) Ici, le principe est le même que sur le web lors d’un crawl: il s’agit d’un processus d’expansion contrôlée qui nous fait passer de liens en liens, le réseau de citations permettant de collecter des données précises sur la topologie réelle du corpus. C’est le principe du breath first search en web mining où l’on étend un corpus de pages à partir d’une ou plusieurs URL de départ (seed) en suivant les liens qui font passer à chaque itération à différents niveaux de profondeur ou de distance. Du brevet choisi comme « seed », le corpus a été tendu à plus de 10.000 brevets, corpus ensuite filtré en ne retenant que les brevets ayant au moins deux liens (entrants oui sortants). Les quelques 1200 brevets restant ont été indexés et traduits en structures de graphes exploitables à partir de Gephi.
La méthode présente des avantages, notamment en termes de stratégie d’extraction de l’information: par expérience des univers de documents numériques, nous nous attendons à ce que les brevets soient organisés comme une série distinctes d’agrégations et que, par conséquent, la distribution des liens de citations comme les indicateurs de contenu (les mots-clés présents dans les titres ou les résumés par exemple, indexés dans une table) convergent, illustrant le principe général de « corrélation contenu-structure » qui a permis, notamment, de développer de nombreuses technologies pour le web. En partant d’un brevet riche en liens de citation (entrante et sortante), on peut supposer que le processus d’extraction nous mènera rapidement à différents autres brevets (ou d’autres points majeurs de la structure explorée), voire (peut-être) à des zones en périphérie où la densité de liens se réduit, « quelque-part » où le processus d’agrégation diminue. Si la méthode suppose le développement d’une structure d’indexation (ce qui représente un travail non-négligeable), elle peut se révéler efficace si, effectivement, ce qui est « similaire » ou « complémentaire » du point de vue du « contenu » (ou du thème), est aussi lié dans une structure de graphe (ici par citations). Nous avons fait le pari que les notices de brevets font partie de ces univers documentaires comme les moteurs de recherche web, les bases de notices bibliographiques, les textes de loi où similarité/complémentarité des contenus se confondent en grande partie avec ce qui est proche ou lié. Notons que nos collègues américains ont forgé il y a déjà plus de 10 années l’expression synthétique de topical localities, un principe générique qu’ils appliquent aussi bien aux brevets qu’aux notices bibliographiques, en passant par les réseaux sociaux et, surtout, les milliards de pages web indexées.
UNE BOUSSOLE. Reste la fameuse phase « d’exploration » du corpus. Le terme résonne de promesses (comme celui de knowledge discovery) et recouvre une grande richesse de pratiques qui se développent aujourd’hui, notamment autour des grands jeux de données (les fameuses data). Cependant, l’expression a besoin d’être précisée, notamment parce qu’il est bon de rappeler que les « vues » (‘insights ») sur les données sont construites par le cartographe au terme d’un parcours où se mêlent cognition et instrumentation. Les solutions de visualisations automatiques, elles-mêmes, n’ont rien de « naturel » (si le terme a encore un sens dans cet univers). Après s’être longuement exercé avec Antoine Le Calvez depuis plusieurs mois, il me semble que des « réflexes » ou des « procédures » ont fini par s’imposer et que l’exploration d’un corpus de données (en phase initiale de description) obéit à des « directions » complémentaires, et implicitement articulées. Une étude précise en termes d’usage montrerait probablement qu’en phase d’exploration ou de découverte d’un corpus, les opérations instrumentées d’investigation obéissent à des orientations générales que l’on peut synthétiser sous la forme d’une « boussole » et qui peuvent rappeler, à certains égards, les dimensions tant qualitatives que quantitatives de tout traitement logique de l’information. La boussole d’exploration des données me semble synthétiser les grandes directions cardinales qu’épousent les cartographes de l’information et, au-delà peut-être, n’importe quel usager dans son utilisation d’un système cartographique d’information. Et, en ce sens, la cartographie d’information a tout d’une cinématique.
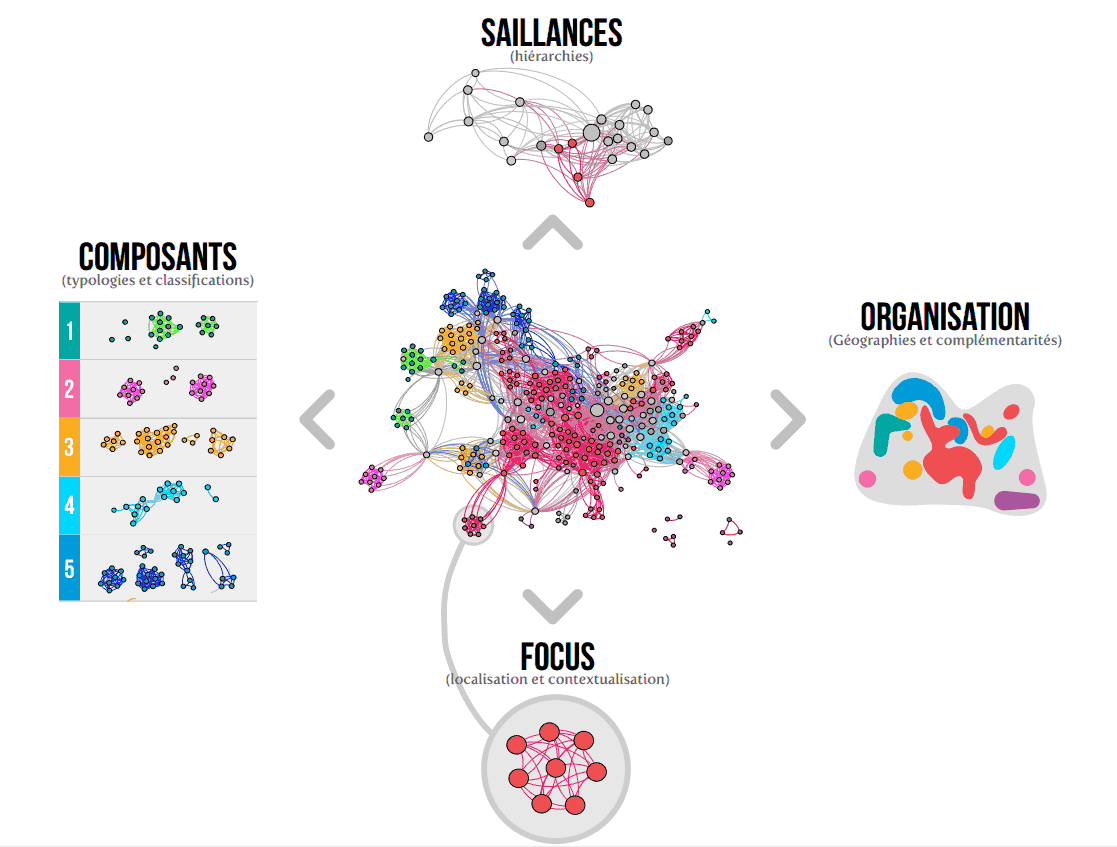
Saillances et focus: la capacité, à partir des données de départ, de faire varier la vue, soit en direction des éléments les plus « structurants » (saillances), soit localement en direction de certains sous-ensembles (focus). On peut y voir l’équivalent du « zoom » cinématographique. Ces variations peuvent emprunter de nombreuses formes en termes de traitement des données, notamment dans la recherche des éléments saillants d’un corpus qui passe souvent par la mobilisation d’algorithmes de classement (ranking), de filtres et de seuils statistiques. On peut ainsi hiérarchiser les noeuds d’un graphe en fonction de différentes propriétés de structure (comme le degré, entrant ou sortant, des scores de betweeness centrality, de PageRank…) et filtrer quantitativement l’ensemble du graphe en fonction du « trait pertinent » retenu. Apparaît alors une sorte de « squelette » du corpus, révélant les éléments les plus importants en termes de visibilité ou de centralité. Le focus, ou le « zoom », relève du même processus: la réduction quantitative du corpus s’effectue selon des critères de localités topologiques (par exemple une zone qui semble s’autonomiser en périphérie du graphe sous l’effet des forces d’attraction-répulsion d’un algorithme de spatialisation comme les ForceAtlas ou bien encore un ensemble de noeuds associés statistiquement à une classe de modularité) ou bien selon des critères sélectifs liés à des attributs des noeuds. Saillances et focus permettent au cartographe d’explorer des propriétés génériques du jeu de données, soit en faisant apparaître « l’ossature » ou la « colonne vertébrale » d’un jeu de données (ce que ne permet pas une liste à plat manifestant un classement hiérarchique), soit en plongeant dans l’étude de propriétés locales.
Composants et organisation relèvent d’une démarche complémentaire. Il s’agit pour le cartographe d’isoler les sous-ensembles constitutifs (ou sous-graphes) du corpus, ses « régions » si l’on veut, et de comprendre la ou les logiques qui préside(nt) à leur distribution. Si dans le cas des saillances et des focus il s’agissait de « monter » ou « descendre » dans la vue, avec les composants et l’organisation il s’agit de « tourner » autour des données. Nous sommes proches ici du jeu de puzzle et des démarches d’appariement (logique et graphique). La capacité à discerner des « composants » dans un ensemble de données sous forme de graphes n’est cependant pas simple: on peut faire jouer des partitions possibles à partir des attributs des noeuds et/ou des liens (par exemple à partir d’une classification préalable) ou, de façon complémentaire, faire émerger des classes statistiques. Dans une démarche exploratoire, la décomposition du graphe s’annonce d’autant plus prometteuse que la recherche de classes statistiques (modularity) correspond globalement aux clusters qui se dessinent visuellement par attraction-répulsion comme dans le cas de notre corpus de notices de brevets (à tel point que l’on peut aussi décomposer un composant à un second niveau d’analyse). Cependant, l’exploration de l’organisation d’un corpus peut se révéler ardue quand le « coefficient de décomposition » est faible (c’est le cas souvent des graphes aléatoires ou, encore, des graphes dans lesquels la densité de liens est telle qui rien ne semble distinguer des sous-ensembles). Les outils du cartographe (et ses facultés de compréhension!) étant limités, je n’hésite pas, quand cela est possible, à faire appel à un expert du domaine cartographié pour vérifier avec lui s’il n’existe pas une logique de distribution des données jusque-là inaperçue ou peu perceptible avec les instruments cartographiques. Le recherche d’une organisation consiste à positionner les composants les uns par rapport aux autres afin d’identifier si des « formules de complémentarité » président à leur assemblage. Apercevoir des logiques de voisinage dans des masses de données constitue un élément central de la démarche cartographique, un sujet encore trop peu étudié jusqu’à présent. Sur ce point, il est bon de rappeler combien il est important de produire de multiples vues sur les données en faisant varier la palette des métriques, les choix de spatialisation et, surtout, les différentes facettes que proposent la batterie d’attributs associées à chacun des noeuds du système. Donc, autant d’occasions de fixer des vues sur le corpus et, éventuellement, d’imaginer de parcours guidés et scénarisés.
2) Géographie générale du corpus. Spatialisés, les 1279 notices de brevets et leurs 3569 liens de citation apparaissent comme formant un réseau dense de technologies complémentaires, avec des clusters locaux et des liens transversaux (dont le portrait statistique correspond à un modèle de type power-law). La vue générale, notre premier cliché, est déjà réglée selon des paramètres maintenant « classiques »: spatialisation des noeuds (notices de brevets) et des liens avec l’algorithme ForceAtlas2, variations des tailles de noeuds selon le degré entrants ou sortants (ou, ici, nombre de citations), distribution des couleurs à partir de l’algorithme modularity (algorithme de « détection de communautés ») pour donner une première idée des composants. C’est de cette vue, ou de cette première transformation des données, que naîtront les autres vues, organisées selon le principe de la boussole d’exploration.

A grande échelle, la distribution des liens et des noeuds dessine à cette échelle ce qu’il faut appeler une topologie documentaire. Elle possède des propriétés statistiques issues des métriques appliquées aux structures de graphes qui ne sont pas sans évoquer les dimensions physiques d’un objet que l’on pourrait saisir manuellement: densité de liens, diamètre moyen des chemins entre les noeuds, scores de visibilité (ranking) de différentes natures, identification des flux de citation entre les notices citantes et citées. Les jeux de forces d’attraction et de répulsion du ForceAtlas2, en rapprochant ou en éloignant les noeuds en fonction du nombre et de la direction de leurs liens mutuels, renforcent l’effet. Mais il manque un type de filtres qui permettrait d’apercevoir la dimension « sémantique » de la distribution des contenus dont la première spatialisation semble indiquer quelques propriétés. L’emprunt à l’optique n’est pas anodin: les filtres sont des types de calcul appliqués aux données destinés à révéler (ou non) des propriétés qui composent un tableau, aussi bien statistiquement que visuellement avec Gephi. Ici, pour chacun des clusters (par couleur), nous avons isolé une série de mots-clés les plus présents dans les titres des brevets (une quinzaine en général) pour composer un label temporaire pour chaque « région ». Ce « filtre thématique » appliqué à la première vue permet d’apercevoir l’organisation possible des localités:

Le regard exercé d’un spécialiste de l’économie numérique ou de l’histoire des technologies verrait peut-être déjà toute une géographie de la propriété intellectuelle, avec ses domaines au coeur du développement des technologies de compression des images et du son (cluster rouges, jaunes et violets). Il pourrait ainsi deviner, grâce aux titres des régions, où se concentrent les différents savoirs-faires industriels en termes d’application, les premiers standards liés à l’ancien « vidéo CD » (et le MP3), en passant par le « MPEG-2 » et ses applications à la télévision numérique (terrestre, satellite, câble) avec ses fonctionnalités de contrôle des copie (cluster vert), jusqu’aux applications actuelles (mobilité, GPS, interfaces polysensorielles, biofeedback…clusters bleu et rose de droite). Ces deux derniers clusters annoncent peut-être l’un seulement des multiples domaines de déploiement de la norme MPEG-4 dédié à l’interactivité d’objets numériques et aux technologies web et mobiles (streaming, TVHD mobile, services multimédia en ligne…). Issus d’un travail collectif de normalisation, ces formats sont ouverts, mais non libres puisque leur utilisation est soumise au paiement de redevances et mêlent des domaines d’application technologique où dans lesquels se trouvent mêler des géants de l’industrie (Sony, Dolby, Microsoft…). Pour plus d’acuité, il faudrait accompagner le travail d’exploration du cartographe du regard de l’expert dont les connaissances enrichiraient sûrement l’efficacité des instruments ou les procédures de traitement de l’information. Ce type d’expérience reste encore (trop) rare et il faut souhaiter qu’à l’avenir les gestionnaires de contenus (notamment les éditeurs, quel que soit le domaine) partagent avec nous une façon inédite d’explorer leur propre patrimoine.
3) Saillances. L’étape suivante de la démarche d’exploration consiste à identifier des éléments saillants dans un corpus de données permet aussi d’en comprendre l’organisation. Le calcul des « saillances » dans les données numériques sont particulièrement lié aux opérations de classement ou de hiérarchisation (ranking) telles que les pratiquent les moteurs de recherche (les scores de PageRank par exemple accessibles depuis Gephi). En marge des technologies web, des très grandes masses de données et des questions d’optimisation des calculs et des process, le temps plus long d’une approche exploratoire sur de plus « petits » corpus permet de multiplier les critères de classement, et donc d’accumuler les indices de hiérarchisation et les vues (y compris visuelles). Ici, notre idée est de composer un tableau synthétique regroupant une série de visualisations différentes qui rendent compte des brevets les plus cités (qui ne sont pas forcément les plus anciens).

Cette série de prises visuelles, une fois assemblées, permet d’éclairer les différentes facettes de cette « couche » proéminente de notices, sous forme de listes à plat ou en vue circulaire, sous forme de graphes de mots-clés pour saisir la ou les thématiques générales de cette « couche haute » du corpus et sans oublier la « carte générale » où apparaissent les éléments dans leurs positions réciproques à l’échelle du corpus. On passe ainsi du simple classement ou de la liste ordonnée à une recherche plus générale de « la colonne vertébrale » du corpus. C’est ce qui motive, en général, l’idée de mêler vue globale et éléments de hiérarchie en faisant varier des dimensions graphiques comme la taille des noeuds ou leurs couleurs (comme on vient de le voir en bleu avec l’affichage associé des titres des brevets). Cependant, étant donné le nombre important de nouvelles fonctionnalités implémentées dans Gephi (voir le marketplace), on peut emprunter d’autres voies en termes de visualisation des saillances. Entre autres, la fonction « coordonnées » permet de distribuer les données selon des valeurs, par exemple en fonction des identifiants des brevets et le nombre de liens entrants. C’est le principe de ce que l’on appeler la « vue latérale ».

L’idée consiste à faire « pivoter » virtuellement le graphe pour l’appréhender de façon latérale. Couplée à une notre première spatialisation générale, le procédé permet  d’explorer le corpus comme un ensemble d’aspérités, rappelant des sensations tactiles comme celles de ces anciennes cartes géographiques en relief que l’on parcourait aussi de la main. Pour rendre la « vue latérale » entièrement compatible avec la vue générale, nous avons reproduit l’expérience en respectant l’ordre de projection des clusters ainsi que la distribution de leurs couleurs selon les classes de modularité. De là, la déclinaison du procédé pour faire apparaître « en relief » les notices les plus citées comme les plus citantes.
d’explorer le corpus comme un ensemble d’aspérités, rappelant des sensations tactiles comme celles de ces anciennes cartes géographiques en relief que l’on parcourait aussi de la main. Pour rendre la « vue latérale » entièrement compatible avec la vue générale, nous avons reproduit l’expérience en respectant l’ordre de projection des clusters ainsi que la distribution de leurs couleurs selon les classes de modularité. De là, la déclinaison du procédé pour faire apparaître « en relief » les notices les plus citées comme les plus citantes.


Une fois calée la procédure dans Gephi, notre album peut s’enrichir d’un nombre potentiellement important de clichés, selon le nombre et le type d’attributs associés aux éléments du corpus. Ces productions sont l’occasion de rappeler combien le travail cartographique permet d’enrichir le corpus de données additionnelles (méta-données). En combinant calculs statistiques et interface de manipulation d’objets spatialisés, Gephi contribue à transformer une démarche exploratoire en processus d’enrichissement continu puisque les résultats de calculs statistiques comme les choix de visualisation peuvent être sauvegardés, et donc archivés dans la structure-même du jeu de données.
4) Focus. Se concentrer sur un élément de la structure générale fait partie des opérations nécessaires à tout travail sur l’information. On peut opérer un focus sur un sous-ensemble (par exemple une classe de modularité) ou bien sur une notice précise. Etant donnés les masses de données accessibles aujourd’hui et leur complexité (éventuelle), les besoins de mise en contexte d’une information se font plus nombreux et plus divers. On peut voir dans le focus l’équivalent du « zoom » que le cinéma a imposé historiquement comme cadre de localisation visuelle des objets ou des personnages. Dans le domaine des notices de brevets, le principe peut être mobilisé pour cerner une thématique précise ou bien pour comprendre les relations d’un portefeuille de brevets d’un industriel avec son environnement concurrentiel. De façon arbitraire, notre focus s’est porté sur une notice d’un brevet particulièrement cité dans son cluster dédié à la mobilité, aux interfaces polysensorielles et aux technologies de géoréférencement, « Storing and recalling information to augment human memories ».

Gephi propose plusieurs solutions de contextualisation possibles : colorer le noeud choisi, faire varier sa taille, le situer dans son sous-réseau de liens de citations, de citer les noms des brevets avec lesquels il est associé ou encore le placer dans une vue circulaire qui permet de comprendre les relations qu’il entretient avec ses voisins proches. Les possibilités de focus sont d’autant plus grandes que Gephi permet de « copier-coller » un sous-ensemble du graphe et de reproduire à petite échelle l’ensemble des calculs et de procédures.
5) Composants. La recherche de composants est une opération-clé en matière d’analyse de données mais aussi de cartographie car elle permet de discerner des frontières internes et de délimiter des « régions » dans la géographie documentaire générale. Elle repose sur la capacité à repérer des qualités communes (disons, concentrées) à un sous-ensemble de noeuds pour en délimiter les frontières. Evidemment, on comprend alors que cette capacité varie selon le nombre et la qualité des informations associées à chacun des éléments du système. En phase d’exploration, et sans être expert des différents domaines technologiques associés au MPEG, l’algorithme Modularity permet de faire émerger différentes classes statistiques, avec la possibilité de faire varier l’échelle de résolution (on peut contraindre l’algorithme à discerner une multitude de petites classes ou bien seulement deux). Cet algorithme est un instrument pertinent pour faire émerger des classifications ascendantes, notamment à partir de calculs opérés sur la distribution des liens entre les noeuds. De là viennent les 8 composants colorés qui forment nos clusters et auxquels nous avons essayé de donner un titre provisoire pour évaluer globalement leur pertinence thématique.

La recherche de composants dans une structure que l’on peut qualifier de « complexe » pose d’intéressants problèmes en termes de méthodologie de traitement des données. Il en pose aussi au cartographe d’information, notamment quand il hérite de catégories préconstruites par des utilisateurs et qui constituent les principaux instruments de rangement et de manipulation de l’information. La cartographie d’informations constitue un terrain exemplaire de confrontation entre classifications héritées et classifications émergentes, terrain enrichissant mais aussi délicat car, parfois, les données semblent laisser apercevoir des composants et une organisation assez différents de ceux utilisés couramment pour gérer l’information et souvent implémentés dans un système. Gephi permet de faire varier partitions héritées (et présentes dans les méta-données) et opérations de clustering (clusters pouvant à leur tour être adoptés comme catégories de classification). Le développement de confrontations problématiques entre démarche exploratoire (bottom-up) et classification héritées (top-down où les noeuds sont rangés obligatoirement dans des catégories préexistantes) est l’une des conséquences de la numérisation des grands corpus de données sur lesquels on peut alors faire porter, indépendamment de toute classification imposée, des processus d’exploration sur les différentes dimensions de l’information.
6) Organisation et temporalité. la recherche de saillances, les variations de focus et le dénombrement de composants permettent maintenant d’apercevoir l’organisation générale du corpus, avec ses zones possibles de spécialisation et leur distribution en termes de  voisinage. Cependant, le filtre de zonage qui permet de produire des « mini-map » (et donc de figer la vue de façon synthétique) ne doit pas faire oublier que l’organisation que nous avons sous les yeux est le produit d’un processus historique de dépôts, comme autant de couches temporelles successives. Dans les domaines des notices de brevets comme des publications scientifiques ou des textes de loi, organisation et temporalité se confondent (modélisables sous forme de graphes orientés acycliques). Les problématiques associées à la question du « temps dans les données » sont nombreuses, qui plus est pour ce type d’informations (et l’on sait combien importe aux spécialistes de la propriété intellectuelle le principe de la « recherche d’antécédents »). Nous n’avons fait que les effleurer au cours de notre expédition mais elles posent d’emblée des questions auxquelles le cartographe se trouve rapidement confronté. En termes de méthodologie tout d’abord puisque la mesure du temps suppose le choix d’un étalon (le mois? L’année? La décennie?), la représentation d’un signal (une courbe? Un historique?) et la capacité à reconnaître (deviner) des « événements » interprétables. En termes de topologie documentaire ensuite car, dans l’univers des brevets, les plus anciens ne sont pas forcément (pour le cartographe) les plus « importants ». Si le plus ancien de nos 10.000 brevets de départ date de 1973, la couche couvrant les années 1990-1995 regroupe la plupart des noeuds citant le plus (les couches anciennes) et cités le plus (par les couches suivantes). Une étude détaillée de cette couche (qui nous donne par ailleurs une idée du type d’intervalle à mobiliser pour comprendre l’évolution globale d’un univers de brevets) permettrait-elle de révéler que la plupart des avancées majeures autour du format MPEG ont été réalisées durant cette période? Enfin, c’est en termes de technique cartographique et de prise de vue que la restitution du temps peut poser de multiples problèmes. Pour une première exploration, nous n’avons fait que prendre quelques clichés en faisant varier les dates comme autant de filtres visuels appliqués aux données. En particulier, nous avons retenu le segment des années 2000-2012 pour essayer de comprendre « où » apparaissent les notices les plus récentes dans la géographie générale en allumant de rouge les noeuds concernés.
voisinage. Cependant, le filtre de zonage qui permet de produire des « mini-map » (et donc de figer la vue de façon synthétique) ne doit pas faire oublier que l’organisation que nous avons sous les yeux est le produit d’un processus historique de dépôts, comme autant de couches temporelles successives. Dans les domaines des notices de brevets comme des publications scientifiques ou des textes de loi, organisation et temporalité se confondent (modélisables sous forme de graphes orientés acycliques). Les problématiques associées à la question du « temps dans les données » sont nombreuses, qui plus est pour ce type d’informations (et l’on sait combien importe aux spécialistes de la propriété intellectuelle le principe de la « recherche d’antécédents »). Nous n’avons fait que les effleurer au cours de notre expédition mais elles posent d’emblée des questions auxquelles le cartographe se trouve rapidement confronté. En termes de méthodologie tout d’abord puisque la mesure du temps suppose le choix d’un étalon (le mois? L’année? La décennie?), la représentation d’un signal (une courbe? Un historique?) et la capacité à reconnaître (deviner) des « événements » interprétables. En termes de topologie documentaire ensuite car, dans l’univers des brevets, les plus anciens ne sont pas forcément (pour le cartographe) les plus « importants ». Si le plus ancien de nos 10.000 brevets de départ date de 1973, la couche couvrant les années 1990-1995 regroupe la plupart des noeuds citant le plus (les couches anciennes) et cités le plus (par les couches suivantes). Une étude détaillée de cette couche (qui nous donne par ailleurs une idée du type d’intervalle à mobiliser pour comprendre l’évolution globale d’un univers de brevets) permettrait-elle de révéler que la plupart des avancées majeures autour du format MPEG ont été réalisées durant cette période? Enfin, c’est en termes de technique cartographique et de prise de vue que la restitution du temps peut poser de multiples problèmes. Pour une première exploration, nous n’avons fait que prendre quelques clichés en faisant varier les dates comme autant de filtres visuels appliqués aux données. En particulier, nous avons retenu le segment des années 2000-2012 pour essayer de comprendre « où » apparaissent les notices les plus récentes dans la géographie générale en allumant de rouge les noeuds concernés.

Le procédé peut être mobilisé pour produire une série de vues ou des frises temporelles comme ici. Un autre procédé aurait pu consister à produire une vue cumulative où les éléments apparaissent (ou disparaissent comme dans Gephi avec la time-line) en fonction des segments temporels considérés. Dans les deux cas, pertinents pour des imprimés, la visualisation de la dynamique dans les données appelle la cinétique numérique. A peine survolée, la géographie temporelle du corpus laisse déjà apercevoir quelques détails, notamment dans la période la plus récente (2011-2012) où les nouvelles notices apparaissent concentrées dans le même cluster et où les nejeux des brevets portent sur un domaine où sont liés les termes « data », « computer », « high definition video » et « interpolation of video compression frames ». On pourrait voir dans ce type de frise chronologique appliquée à une carte (graphe) les prémisses d’un outil de veille règlementaire et juridique. Mais d’autres solutions viendront à coup sûr prochainement, notamment du côté de tous ceux qui sont plongés des univers construits sur des tweets ou des commentaires de blogs, autrement plus difficiles techniquement à mesurer que le temps long des brevets.
7) Les assignees, par couches. La visualisation des principaux ayants-droits (personnes physiques ou morales) constitue un objectif central pour la cartographie de notices de brevets. Contextualiser son portefeuille de brevets, repérer les acteurs concurrents ou les domaines émergents, aider à la recherche d’antécédent constituent des opérations où la cartographie peut être d’une grande aide (à des fins de compréhension comme de communication publique). Cependant, bien des solutions restent encore à inventer dans ce domaine, à la condition préalable que les fameuses « affiliations » soient correctement indexées (ce qui n’est pas gagné sur les bases existantes, y compris dont l’accès est payant). Après un travail de normalisation des appellations, nos 1500 notices peuvent être associées à plus de 350 entités (en grande majorité des entreprises). Voici les principales, un florilège des « géants » de l’industrie des contenus numériques :
AEG Aktiengesellschaft(Ulm DE)AT&T Bell Laboratories(Murray Hill NJ)ATI International SRL(BB)Adobe Systems Incorporated(San Jose CA)Agfa Corporation(Wilmington MA)Airworks Corporation(Nassau BS)Alcatel NA Network Systems Corp.(Raleigh NC)Apple Computer Inc.(Cupertino CA)Atari Inc.(Sunnyvale CA)Autodesk Inc.(San Rafael CA)Avanced Micro Devices Inc.(Sunnyvale CA)Bell Atlantic Network Services Inc.(Arlington VA)Bridgestone Corporation(Tokyo JP)British Broadcasting Corporation(London GB2)CBS Inc.(New York NY)California Institute of Technology(Pasadena CA)Canadian Patents & Development Ltd.(Ottawa CA)Canon Kabushiki Kaisha(Tokyo JP)Carnegie Mellon University(Pittsburgh PA)Compaq Computer Corporation(Houston TX)Cornell Research Foundation Inc.(Ithaca NY)Daewoo Electronics Co. Ltd.(Seoul KR)Discovision Associates(Long Beach CA)Dolby Laboratories Licensing Corporation(San Francisco CA)Eastman Kodak Company(Rochester NY)Exxon Production Research Company(Houston TX)Fuji Photo Film Co. Ltd.(JP)Fujitsu Semiconductor Limited(Yokohama JP)General Electric Company(Princeton NJ)Google Inc.(Mountain View CA) |
Hitach Ltd.(Tokyo JP)Honeywell GmbH(Offenbach DE)Intel Corporation(Santa Clara CA)Intelligent Instruments Corporation(Santa Clara CA)Kabushiki Kaisha Toshiba(Tokyo JP)Korea Telecom(Seoul KR)L’Etat Francais (CNET)(both of FR)Telediffusion de France(both of FR)Lucent Technologies Inc.(Murray Hill NJ)Macrovision Corporation(Mountain View CA)Massachusetts Institute of Technology(Cambridge MA)Matsushita Electric Industrial Co.(Osaka JP)McDonnell Douglas Corporation(St. Louis MO)Microsoft Corporation(Redmond WA)Mitsubishi Denki Kabushiki Kaisha(JP)Motorola Inc.(Schaumburg IL)NVIDIA International Inc.(St. Michael BB)Namco Ltd.(Tokyo JP)Nike Inc.(Beaverton OR)Nippon Electric Co. Ltd.(Tokyo JA)Nippon Hoso Kyokai(Tokyo JP)Nippon Kogaku K.K.(Tokyo JP)Nippon Steel Corporation(Tokyo JP)Nippon Telegrpah and Telephone Public Corporation(Toyko JP)Nokia Corporation(Espoo FI)North American Philips Corporation(New York NY)Olympus Optical Co. Ltd.(Tokyo JP)Panasonic Corporation(Osaka JP)Philips Electronics North America Corporation(New York NY)Pioneer Corporation(Tokyo-to JP)Polaroid Corporation(Cambridge MA) |
RCA Thomson Licensing Corporation(Princeton NJ)Ricoh Company Ltd.(JP)Rockwell Science Center LLC(Thousand Oaks CA)SGS-Thomson Microelectronics S.A.(Saint Genis Pouilly FR)STMicroelectronics S.A.(Montrouge FR)Sanyo Electric Co. Ltd.(Osaka JP)Schlumberger Technology Corporation(New York NY)Sharp Kabushiki Kaisha(Osaka JP)Siemens Aktiengesellschaft(Berlin & Munich DE)Sony Corp.(Tokyo JP)Stanford University(Stanford CA)Sun Microsystems Inc.(Palo Alto CA)Technicolor Videocassette Inc.(Camarillo CA)Texas Instruments Incorporated(Dallas TX)The Belgian State(Brussels BE)The Board of Trustees of the University of Illinois(Urbana IL)The Boeing Company(Seattle WA)The Marconi Company Limited(London EN)The Regents of the University of California(Oakland CA)The Research Foundation of State Univ. of N.Y.(Albany NY)The Trustees of Columbia University in the City of New York(New York NY)The United States of America as represented by the Secretary of the Navy(Washington DC)Thomson-CSF(Paris FR)Time Warner Entertainment Company L.P.(Stamford CT)U.S. Philips Corporation(New York NY)Xerox Corporation(Stamford CT)Yamaha Corporation(Hamamatsu JP) |
Dans une perspective réseaux, chacun des (principaux) acteurs industriels peut être représenté sous le forme d’un noeud dont les liens avec les autres acteurs peuvent être calculés comme la somme des liens entrants ou sortants de leurs différents brevets.  Autrement dit, il s’agit d’un processus de d’agrégation de données où les notices et leurs propriétés sont regroupées par assignee (procédé qui préside, notamment, à l’établissement des « cartes des sciences » à grande échelle). Ce type de graphe a l’avantage (avec Gephi) d’attribuer des couleurs en fonction de celle du noeud « source », autrement dit les liens citants. Cependant, l’aperception de la dimension temporelle fait défaut dans un domaine où l’antécédence temporelle est une dimension majeure. La présence des principales dates de dépôt de brevets associées aux labels étant faiblement instructive dans une spatialisation purement « force directed » (ForceAtlas), cela a été l’occasion des tester plusieurs autres types de vues, tout en respectant la présence des liens de citation de brevets à brevets entre les 15 industriels les plus présents dans notre corpus.
Autrement dit, il s’agit d’un processus de d’agrégation de données où les notices et leurs propriétés sont regroupées par assignee (procédé qui préside, notamment, à l’établissement des « cartes des sciences » à grande échelle). Ce type de graphe a l’avantage (avec Gephi) d’attribuer des couleurs en fonction de celle du noeud « source », autrement dit les liens citants. Cependant, l’aperception de la dimension temporelle fait défaut dans un domaine où l’antécédence temporelle est une dimension majeure. La présence des principales dates de dépôt de brevets associées aux labels étant faiblement instructive dans une spatialisation purement « force directed » (ForceAtlas), cela a été l’occasion des tester plusieurs autres types de vues, tout en respectant la présence des liens de citation de brevets à brevets entre les 15 industriels les plus présents dans notre corpus.

Dans cette recherche d’une vue synthétique temporelle, la « vue horizontale » a fait l’objet d’un cliché plus détaillé en réglant quelques paramètres: sélection des 5 assignees possédant le nombre le plus élevé de brevets (taille des noeuds), distribués sur un axe horizontal (en fonction d’un score pondéré de liens sortants) laissant ainsi la place pour afficher les années où se sont concentrées le plus grand nombre de dépôts. Les 10 autres acteurs sont placés sur un axe verticale, ce qui permet de représenter leur degré d’antécédence. En conservant le principe de la coloration des liens de citation en fonction de la couleur de source, on aperçoit rapidement qui sont les acteurs majeurs, leur liens (éventuels) de citation mais aussi les relations qu’ils entretiennent ensemble avec des acteurs plus anciens qui ont déjà développé des procédés ou des technologies complémentaires ou concurrentes.

Le rôle prépondérant de Microsoft en termes de nombre de brevets et de flux de citations (notamment vers les brevets SONY) paraît indiscutable. S’il faut rester prudent quant à la relativité de notre démarche (par exemple, notre carte générale n’est constituée que de 1500 notices sur des dizaines de milliers possibles), un événement est entré en résonance avec notre exploration cartographique de notre corpus. Pendant que nous rédigions ces lignes avec Antoine Le Calvez, plusieurs grands médias se sont fait l’écho de la conférence de presse où les dirigeants de Microsoft ont annoncé une refonte complète de l’organisation de la société. Alors que la vente des PC recule de 11% au semestre dernier (et donc la vente de Windows), que Windows se révèle un échec relatif et que le marché juteux des supports mobiles est dominé par Apple et Google, Microsoft entend développer un « écosystème » des données orienté autour de la mobilité, des services et de l’interactivité alors que jusque-là régnait des divisions par produits (le système d’exploitation Windows, la suite logicielle Office, le moteur de recherche Bing, le système d’exploitation Windows Phone, la console Xbox…). Nous ne saurions évaluer les atouts que possède Microsoft pour cette entrée de plein dans l’univers des données distribuées, de la conception des dispositifs mobiles ou du degré d’innovation des nouveaux services en lignes qui seront proposés au public. Cependant, sachant que les formats MPEG y jouent un rôle majeur (notamment pour la vidéo), nul doute que le terrain a été préparé de longue date par la firme de Redmont.
Franck Ghitalla, Antoine Le Calvez (avec l’aide de l’Atelier Iceberg).

Article très intéressant,
Notez que le graphe des citations de brevets n’est pas nécessairement acyclique. Par exemple, un brevet en cours de dépôt peut être cité par un brevet qui pourrait être validé plus vite. Le processus de validation d’un brevet peut durer de quelques mois à plusieurs années, et on considère plusieurs dates de « dépôt ». Ce temps varie à cause du temps de traitement par l’office des brevets concernés, les différents allers-retours pour convenir du document final, mais aussi à cause de la stratégie du déposant, qui peut avoir intérêt à se dépêcher ou à traîner les pieds, un brevet ayant une durée de validité limitée une fois la version finale acceptée et publiée. Il faut donc faire attention à ce qu’on appelle l’antériorité d’un brevet.
Par ailleurs, la pratique des citations varie selon les offices : aux US il faut lister un maximum de références (exhaustivité), tandis qu’en Europe on restreint à une petite liste la plus représentative. J’ai oublié comment ça se passe au Japon. Et bien sûr, omettre une référence très pertinente peut se révéler intéressant pour éviter de trop révéler le procédé de l’invention…ça peut passer si l’office fait mal son travail de vérification et omet de demander le rajout de ladite référence.
N’oublions pas qu’un brevet est un compromis trouvé entre le déposant et l’office : le déposant doit dévoiler suffisamment d’informations pour que l’invention devienne une connaissance partagée (c’est une publication) mais si possible en évitant que d’autres concurrents fassent mieux en reprenant ses efforts de recherche. De plus, les « claims » doivent permettre de démontrer le caractère nouveau de l’invention et doivent protéger au mieux l’invention, mais plus elles couvrent de choses et plus il est difficile de prouver la nouveauté, cependant plus elles sont restreintes et moins elles ont de valeur. Il est donc courant de diviser un brevet en plusieurs brevets…sans que ces brevets se citent entre eux. Enfin, un brevet n’a de valeur que s’il peut être protégé, et l’inventeur peut décider de ne déposer un brevet que sur une sous-partie de son invention. Et puis il existe le coup classique de déposer des brevets inutiles, juste pour dérouter la veille des concurrents. Tout ceci impacte sur le choix des références.
Une autre remarque sur la méthode de « crawling », elle correspond aussi au « snowball sampling » : https://en.wikipedia.org/wiki/Snowball_sampling
Dont les limites et les biais sont très bien étudiés.
Merci Sébastien pour les infos. Tu as raison d’insister sur tout l’aspect stratégie de dépôt, le travail des offices et, donc, sur les conséquences en termes de données (notamment sur la distribution des liens de citation). Nous n’avons guère traité ces aspects, en voulant insister plutôt sur l’aspect cartographique. En règle générale, avec l’Atelier Iceberg notamment, nous travaillons de concert avec le service ou la personne spécialiste de la question dans les entreprises ou les organismes de recherche, qui connaît sur le bout des doigts les aspects que tu soulignes.
Merci pour le voyage! Je n’ai jamais exploré ces pistes.
De mon coté je « cartographie les brevets » pour 3 usages :
– identifier les communautés d’inventeurs et les gourous : (en interne ou à la concurrence), par domaines, dans le but de restructuration / réorganisation, recrutement ou investigation. La manip consiste à cartographier « qui co-invente le plus de brevets avec qui, au sein d’une firme » (= les co-inventeurs communs à un set de brevets). Exemple ici : http://fr.slideshare.net/kalidience/the-wind-turbine-champions
– Identifier les champions d’un domaine et/ou anticiper l’évolution des chaines de valeurs entre sous-domaines : (fusion acquisition / achat de license / accords partenriats). Dans ce cas, on définira un domaine puis des sous domaines, par des expressions et mots clés. Ces derniers permettront de remonter un set de brevets dont les résumés contiennent toute ou partie des mots clés et expressions de départ. Ce que l’on cherchera à cartographier, ce sont les liens induits entre les mots clés et expressions d’une part, et les liens entre les déposants et les expressions d’autre part. Exemple sur le domaine du social advertising ici : http://fr.slideshare.net/kalidience/identifiez-les-champions-et-les-chanes-de-valeur-grce-la-cartographie-des-brevets.
Dans tous les cas, le gros du travail consiste – une fois de plus – à nettoyer les données récupérées… Il porte essentiellement sur les noms des déposants et des inventeurs.
fred
Effectivement, c’est encore un autre aspect important de la démarche. Pour ma part, je reste surpris de voir à quel point dans les bases en accès payant le travail de nettoyage est aussi important, comme dans le domaine des notices bibliographiques. La question de la cartographie des communautés d’inventeurs est particulièrement intéressante: nous sommes en train de tester différentes solutions cartographiques appliquées aux brevets du CNRS pour essayer d’esquisser une géographie de l’invention dans le domaine de la recherche fondamentale et appliquée. J’espère que nos expérimentations contribueront aux activités de Kalidience!
Magnifique réalisation ! Je n’avais encore jamais croisé une expérience qui tire si pleinement profit des possibilités de Gephi, je me réjouis de la citer en exemple !
Merci. Il y a encore plein de choses à inventer en termes de manipulation et d’usages avec Gephi.
Article passionnant, en particulier dans la mise en carte des informations !
Nous avons beaucoup travaillé sur les brevets, en approfondissant deux axes : la globalisation de la R&D (Corporate Invention Board, http://www.corporateinventionboard.eu ) et la cartographie de la technologie (présentée ici : http://www.sciences-technologies.eu/fr/thematiques-de-recherche/carte-des-technologies.html ) avec un travail important de reclassification. Nous utilisons la base de données Patstat produite par l’Office Européen des Brevets. Elle a le double avantage de couvrir un très large éventail d’offices (plus de 80 offices comme l’OEB, l’USPTO, l’INPI, JPO pour le Japon, et bien d’autres intéressants comme la Corée du Sud et l’Allemagne), ainsi que de bénéficier d’une communauté assez importante et active (conférence Patstat annuelle axée non pas sur la base elle-même mais sur la mesure de la technologie au sens large).
Une petite précision sur l’importance de l’univers de brevets utilisé. Pour résumer, en fonction de l’histoire d’un brevet, il peut y avoir trois « moments » importants : l’application (correspondant au dépôt du dossier, qui peut être révisé en fonction des évaluations), la publication (le brevet est rendu public, il peut alors être révisé en fonction des évaluations reçues), puis la publication accordée ou pas (si le brevet répond aux critères de l’office, la propriété intellectuelle est accordée sur un territoire donné ou sur un ensemble de pays). Mais si on se place au niveau de l’invention, un brevet n’évolue que rarement seul. Un même brevet, lorsqu’il revêt une certaine importance, est souvent étendu. Il existe deux types d’extensions : les extensions technologiques (le brevet initial est compléter pour en étendre la couverture technologique, comme par exemple l’ajout d’une fonction), et les extensions géographiques (le brevet est entendu pour que la couverture intellectuelle puisse opérer sur un autre territoire, un autre pays). Ainsi on parle de famille de brevets (quelques précisions ici : http://www.sciences-technologies.eu/fr/tag/brevets.html?id=54 ). Une famille ne protège en fait qu’une seule invention. Il existe des familles très larges, et d’autres plus petites. Une manière d’éviter ces doubles comptes, et de se rapprocher de la date réelle d’invention, est de n’utiliser que les brevets prioritaires : ces brevets prioritaires sont les premiers dépôts d’une famille. Ils sont donc des applications. Ils protègent les « ensembles centraux » de l’invention, sans les extensions donc.
Merci pour les exploitations de ces cartes !
Merci Lionel pour ces informations complémentaires. L’univers des brevets recèle donc ses propres règles, parfois surprenantes. Ce premier travail d’exploration s’est depuis poursuivi, en tenant compte des commentaires qui me parviennent. Je note avec intérêt la perspective large donnée par la communauté Patstat sur la mesure des technologies au sens large. Le principe que je poursuis, étude après études, sur les brevets comme sur d’autres objets documentaires, est de capitaliser les données, toutes archivées aujourd’hui par l’Atelier Iceberg et que nous pouvons croiser entre elles. Par exemple, une orientation en matière de politique industrielle, la création d’un Institut de Recherche Technologique ou un ensemble d’appel à projets en recherche fondamentale ou appliquée donnent-ils lieu dans les années qui suivent à des dépôts de brevets? Si oui, sur quels domaines? Etc. C’est ce type de mesures que nous mettons en place de façon à croiser des données, ce qui nous conduit à segmenter fortement nos jeux de données en matière d’analyse de notices de brevets.
Au passage, je note quelques vertus prospectives d’un travail de cartographie: à la fin de notre exploration, Antoine Le Calvez et moi-même avons repéré et insisté sur la présence (récente à l’échelle de la temporalité très lente dans l’univers des brevets) de Microsoft dans le domaine des services distribués de l’image et des données dans notre travail de cet été. Nous avons appris, non sans surprise donc, le rachat de Nokia par Microsoft au début de ce mois de septembre, qui me semble donc tout à fait logique.
Great work!
Is there a english version of this post ?
Google translate isn’t that great but anyways helped to a great extent.
I am working on the same lines to discover tech trends. Any links to similar work, kindly let know.